
AI-analys
Genom att gemensamt utveckla ett digitalt verktyg för analys av lustgasdata kan vi öka värdet av insamlad processdata och skapa ett hjälpmedel för minskningen av lustgasutsläpp.
Lustgasbildning är resultatet av komplexa, icke-linjära och delvis okända bildningsmekanismer som drivs av ett stort antal processparametrar, till exempel syrehalt, recirkulationsflöden och koncentration av olika kvävefraktioner. Det är inte de enskilda processparametrarna var och en för sig, utan kombinationer av dessa, som ger upphov till förhöjda utsläpp. Parametrarna är vidare ofta svåra att mäta kontinuerligt och med hög säkerhet. Detta gör att digitala verktyg, som automatiskt kan bearbeta och analysera mätdata, sannolikt kommer att bli ett hjälpmedel och spela en stor roll för minskningen av lustgasutsläpp.
Insamlade mätdata kan användas för att utveckla och tillämpa fysikaliska mekanistiska datormodeller för att designa och utforma reningsverk som är optimerade för minimal lustgasproduktion. De mekanistiska modellerna utgör också ett slags utbildningsverktyg som ger ökad förståelse för bildningsmekanismerna vilket är en grund för exempelvis experimentplanering och utveckling av lustgasminskande styrstrategier.
Den praktiska tillämpningen av mekanistiska lustgasmodeller i daglig drift begränsas av att det är mycket svårt och tidsödande att hålla dem kalibrerade. Flera studier pekar därför mot att data-drivna digitala verktyg kan erbjuda mer praktiska lösningar i synnerhet för reningsverkets driftsfas. Inom detta initiativ vill vi, gemensamt i VA-sektorn, utveckla och tillämpa ett sådant verktyg.
Syfte och mål
Det digitala verktyget syftar till att minska lustgasemissionerna från vattenreningsprocesser genom analys av processdata. Dessa kan vara automatiska eller manuella.
Det digitala verktyget skall, som funktion av tiden, kunna:
- Prediktera lustgasemissionerna
- Identifiera de huvudsakliga processparametrarna som påverkar emissionerna
Målgruppen för verktyget är utvecklings- och processingenjörer inom organisationerna samt tekniska konsulter och forskare med VA-expertis.
Övergripande funktionsbeskrivning
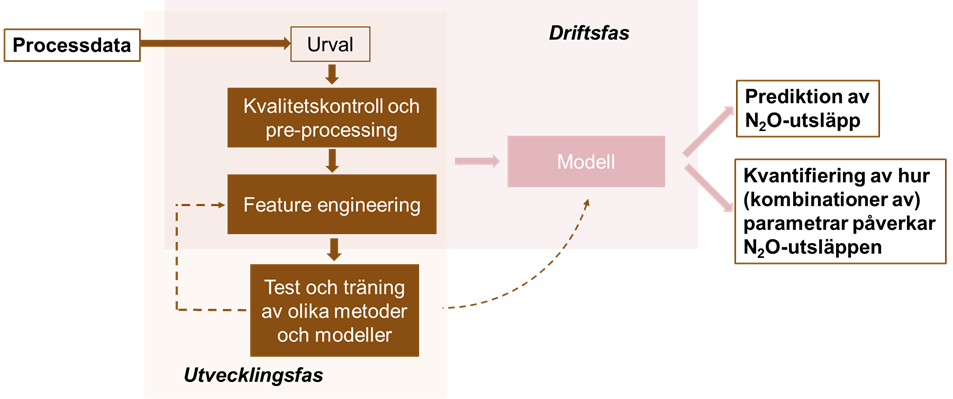
Illustration över den övergripande funktionen för det digitala verktyget
Indata till verktyget är processdata (huvudsakligen online) inklusive mätningar av lustgashalten i frånluften och vattenfasen. Verktyget skall samla in högupplösta data (storleksordning sekund) men kommer utföra beräkningar mer sällan (storleksordning minut-timme).
Verktyget skall innehålla metoder för kvalitetskontroll och förbehandling av indata. Som exempel kan nämnas att uppenbart felaktiga mätvärden, till exempel negativa koncentrationer och frysta värden skall kunna exkluderas automatiskt. Även data från perioder som inte är representativa, som perioder då givare rengörs eller kalibreras, väljs bort.
I AI-sammanhang används begreppet feature synonymt med indata. Efterföljande steg feature engineering är en viktig del av verktyget och innebär att features exkluderas och/eller att nya features skapas med målet att den valda algoritmen skall fungerar optimalt. Skapandet av nya features baseras i hög grad, men inte nödvändigtvis, på domänkunskap. Ett exempel på en ny feature kan vara att ett glidande medelvärde av slamhalten anges som indata. Detta skulle baseras på kunskapen om att slamhalten i biosteget kan påverka lustasbildningen men att den variation i slamhalt som uppkommer och korrelerar med inkommande flöde antagligen inte är relevant.
I verktyget skall det finnas möjlighet att testa och träna/kalibrera olika datadrivna metoder och modeller. Detta beror på att det inte råder konsensus om vilka metoder som är bäst och att detta också kan variera beroende på konfiguration och tillgång till data på varje enskilt reningsverk. Traditionella multivariata statistiska metoder som korrelationsanalys och PCA (prinicipalkomponentanalys) har till exempel använts för att öka förståelsen för samband mellan driftparametrar och lustgasutsläpp. Dessa tekniker erbjuder transparens och enkelhet, men missar ofta viktiga interaktioner. Nyare maskininlärningsmodeller, såsom Random Forest, Support Vector Machines och djupa neurala nätverk som LSTM, har visat starka resultat för prediktion och klassificering av perioder med höga utsläpp. Samtidigt lyfter litteraturen behovet av att förbättra tolkbarheten i dessa modeller för att de ska kunna användas i praktiken och leda till minskade lustgasutsläpp.
Utdata från den valda och tränade modellen skall vara (1) predikterade lustgasutsläpp, och (2) kunskap och rangordning om vilka kombinationer av indata som påverkar emissionerna vid olika tidpunkter. Utdata skall dessutom innehålla indikationer på hur osäkra modellresultaten är.
Genomförande och metodik
I framtida projekt kommer utveckling av verktyget ske i nära samverkan med flera aktörer: forskare och experter inom vattenrening, digitalisering/dataanalys och lustgasbilning samt med operativ personal och beslutsfattare från deltagande reningsverk.
Inledningsvis vill vi utnyttja att vi har tillgång till långa tidserier (flera år) med mätdata från några svenska reningsverk. Lärdomar kommer sedan kunna nyttjas av de reningsverk som inte kommit lika långt.
Det är en önskan att verktyget skall utvecklas och användas av hela den svenska VA-branschen i samverkan och utvecklingen skall därför ske i en öppen och fritt tillgänglig mjukvara, till exempel Python. Tillgång till de senaste versionerna av verktyget kommer att finnas på denna hemsida.
I ett första skede kommer vi att arbeta med data offline för att testa, träna, utvärdera och välja ut metoder. I en andra projektfas skall verktygen implementeras och användas i den dagliga driften. Verktyget integreras då med slutanvändarnas SCADA-system eller implementeras i en IOT-plattform för att kunna supporta mindre anläggningar och VA-organisationer effektivt.
Vill du veta mer om det digitala verktyget för minskade lustgasemissioner?
Kontakta Erik U. Lindblom, IVL och Lunds universitet.